RAID 0
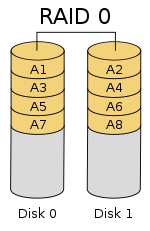
Diagram of a RAID 0 setup
A
RAID 0 (also known as a
stripe set or
striped volume) splits data evenly across two or more disks (
striped) without
parity information for speed. RAID 0 was not one of the original RAID levels and provides no
data redundancy.
RAID 0 is normally used to increase performance, although it can also
be used as a way to create a large logical disk out of two or more
physical ones.
A RAID 0 can be created with disks of differing sizes, but the
storage space added to the array by each disk is limited to the size of
the smallest disk. For example, if a 100 GB disk is striped together
with a 350 GB disk, the size of the array will be 200 GB (100 GB × 2).

The diagram shows how the data is distributed into A
x stripes
to the disks. Accessing the stripes in the order A1, A2, A3, ...
provides the illusion of a larger and faster drive. Once the stripe size
is defined on creation it needs to be maintained at all times.
Performance
RAID 0 is also used in some computer gaming systems where performance
is desired and data integrity is not very important. However,
real-world tests with computer games have shown that RAID-0 performance
gains are minimal, although some desktop applications will benefit.
[2][3]
Another article examined these claims and concludes: "Striping does not
always increase performance (in certain situations it will actually be
slower than a non-RAID setup), but in most situations it will yield a
significant improvement in performance."
[4]
RAID 1

Diagram of a RAID 1 setup
An exact copy (or
mirror) of a set of data on two disks. This
is useful when read performance or reliability is more important than
data storage capacity. Such an array can only be as big as the smallest
member disk. A classic RAID 1 mirrored pair contains two disks (see
reliability
geometrically)
over a single disk. Since each member contains a complete copy and can
be addressed independently, ordinary wear-and-tear reliability is raised
by the power of the number of self-contained copies.
Performance
Since all the data exists in two or more copies, each with its own
hardware, the read performance can go up roughly as a linear multiple of
the number of copies. That is, a RAID 1 array of two drives can be
reading in two different places at the same time, though most
implementations of RAID 1 do not do this.
[5][citation needed]
To maximize performance benefits of RAID 1, independent disk
controllers are recommended, one for each disk. Some refer to this
practice as
splitting or
duplexing (for two disk arrays) or
multiplexing
(for arrays with more than two disks). When reading, both disks can be
accessed independently and requested sectors can be split evenly between
the disks. For the usual mirror of two disks, this would, in theory,
double the transfer rate when reading. The apparent access time of the
array would be half that of a single drive. Unlike RAID 0, this would be
for all access patterns, as all the data are present on all the disks.
In reality, the need to move the drive
heads
to the next block (to skip blocks already read by the other drives) can
effectively mitigate speed advantages for sequential access. Read
performance can be further improved by adding drives to the mirror. Many
older IDE RAID 1 controllers read only from one disk in the pair, so
their read performance is always that of a single disk. Some older
RAID 1 implementations read both disks simultaneously to compare the
data and detect errors. The
error detection and correction
on modern disks makes this less useful in environments requiring normal
availability. When writing, the array performs like a single disk, as
all mirrors must be written with the data. Note that these are best case
performance scenarios with optimal access patterns.
RAID 2
A
RAID 2 stripes data at the
bit (rather than block) level, and uses a
Hamming code for
error correction.
The disks are synchronized by the controller to spin at the same
angular orientation (they reach Index at the same time), so it generally
cannot service multiple requests simultaneously. Extremely high data
transfer rates are possible. This is the only original level of RAID
that is not currently used.
[6][7]
All hard disks eventually implemented Hamming code error correction.
This made RAID 2 error correction redundant and unnecessarily complex.
This level quickly became useless and is now obsolete. There are no
commercial applications of RAID 2.
[6][7]
RAID 3

Diagram of a RAID 3 setup of 6-byte blocks and two
parity bytes, shown are two blocks of data in different colors.
A
RAID 3 uses
byte-level striping with a dedicated
parity
disk. RAID 3 is very rare in practice. One of the characteristics of
RAID 3 is that it generally cannot service multiple requests
simultaneously. This happens because any single block of data will, by
definition, be spread across all members of the set and will reside in
the same location. So, any
I/O operation requires activity on every disk and usually requires synchronized spindles.
This makes it suitable for applications that demand the highest transfer rates in long sequential reads and writes, for example
uncompressed video
editing. Applications that make small reads and writes from random disk
locations will get the worst performance out of this level.
[7]
The requirement that all disks spin synchronously, a.k.a.
lockstep,
added design considerations to a level that didn't give significant
advantages over other RAID levels, so it quickly became useless and is
now obsolete.
[6] Both RAID 3 and RAID 4 were quickly replaced by RAID 5.
[8] RAID 3 was usually implemented in hardware, and the performance issues were addressed by using large disk caches.
[7]
RAID 4

Diagram of a RAID 4 setup with dedicated
parity disk with each color representing the group of blocks in the respective
parity block (a stripe)
A
RAID 4 uses
block-level striping with a dedicated
parity disk.
In the example on the right, a read request for block A1 would be
serviced by disk 0. A simultaneous read request for block B1 would have
to wait, but a read request for B2 could be serviced concurrently by
disk 1.
RAID 4 is very uncommon, but one enterprise level company that has previously used it is
NetApp. The aforementioned performance problems were solved with their proprietary
Write Anywhere File Layout
(WAFL), an approach to writing data to disk locations that minimizes
the conventional parity RAID write penalty. By storing system metadata
(inodes, block maps, and inode maps) in the same way application data is
stored, WAFL is able to write file system metadata blocks anywhere on
the disk. This approach in turn allows multiple writes to be "gathered"
and scheduled to the same RAID stripe—eliminating the traditional
read-modify-write penalty prevalent in parity-based RAID schemes.
[9]
RAID 5
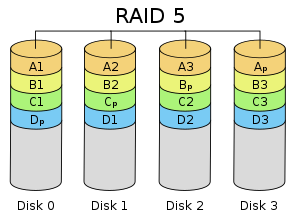
Diagram of a RAID 5 setup with distributed
parity with each color representing the group of blocks in the respective
parity block (a stripe). This diagram shows left asymmetric algorithm
A
RAID 5 comprises block-level striping with distributed
parity. Unlike in RAID 4, parity information is distributed among the
drives. It requires that all drives but one be present to operate. Upon
failure of a single drive, subsequent reads can be calculated from the
distributed parity such that no data is lost. RAID 5 requires at least
three disks.
[10]
RAID 6

Diagram of a RAID 6 setup, which is identical to RAID 5 other than the addition of a second
parity block
RAID 6 extends RAID 5 by adding an additional
parity block; thus it uses
block-level striping with two
parity blocks distributed across all member disks.
Performance (speed)
RAID 6 does not have a performance penalty for read operations, but
it does have a performance penalty on write operations because of the
overhead associated with
parity
calculations. Performance varies greatly depending on how RAID 6 is
implemented in the manufacturer's storage architecture – in software,
firmware or by using firmware and specialized
ASICs for intensive
parity calculations. It can be as fast as a RAID-5 system with one fewer drive (same number of data drives).
[11]
Implementation
According to the Storage Networking Industry Association (SNIA), the
definition of RAID 6 is: "Any form of RAID that can continue to execute
read and write requests to all of a RAID array's virtual disks in the
presence of any two concurrent disk failures. Several methods, including
dual check data computations (
parity and
Reed-Solomon), orthogonal dual
parity check data and diagonal
parity, have been used to implement RAID Level 6."
[12]
Computing parity
Two different
syndromes need to be computed in order to allow the loss of any two drives. One of them,
P
can be the simple XOR of the data across the stripes, as with RAID 5. A
second, independent syndrome is more complicated and requires the
assistance of
field theory.
To deal with this, the
Galois field 
is introduced with

, where
![GF(m) \cong F_2[x]/(p(x))](http://upload.wikimedia.org/math/8/3/7/837e456c5f5cae0a8b6820c3758132c5.png)
for a suitable
irreducible polynomial 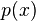
of degree

. A chunk of data can be written as

in base 2 where each
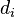
is either 0 or 1. This is chosen to correspond with the element

in the Galois field. Let

correspond to the stripes of data across hard drives encoded as field
elements in this manner (in practice they would probably be broken into
byte-sized chunks). If

is some
generator of the field and

denotes addition in the field while concatenation denotes multiplication, then
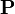
and

may be computed as follows (

denotes the number of data disks):
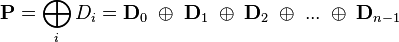

For a computer scientist, a good way to think about this is that is a bitwise XOR operator and  is the action of a linear feedback shift register on a chunk of data.
is the action of a linear feedback shift register on a chunk of data. Thus, in the formula above,
[13] the calculation of
P is just the XOR of each stripe. This is because addition in any
characteristic two finite field reduces to the XOR operation. The computation of
Q is the XOR of a shifted version of each stripe.
Mathematically, the
generator is an element of the field such that
is different for each nonnegative

satisfying
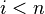
.
If one data drive is lost, the data can be recomputed from
P just like with RAID 5. If two data drives are lost or a data drive and the drive containing
P are lost, the data can be recovered from
P and
Q or from just
Q, respectively, using a more complex process. Working out the details is extremely hard with field theory. Suppose that

and

are the lost values with
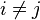
. Using the other values of

, constants

and

may be found so that

and

:
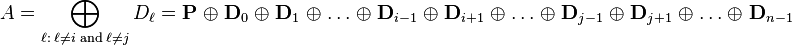

Multiplying both sides of the equation for
by

and adding to the former equation yields

and thus a solution for
, which may be used to compute
.
The computation of
Q is CPU intensive compared to the simplicity of
P.
Thus, a RAID 6 implemented in software will have a more significant
effect on system performance, and a hardware solution will be more
complex.


 Following are the key points to remember for RAID level 1.
Following are the key points to remember for RAID level 1.



 Following are the key points to remember for RAID level 10.
Following are the key points to remember for RAID level 10.





